null변환 함수
nvl, nvl2 함수는 null인 상황에 다른 값으로 반환할 수 있다
null은 숫자도 문자열도 아닌 사용할수 없는값
null은 연산되면 null이 나온다
사용법
nvl(컬럼명, nul일때 제공할 값) => 컬럼의 데이터형과 일치하는 값만 사용할 수 있다.
nvl2(컬럼명,null이 아닐때 제공할 값, null일때 제공할 값)
null인지 아닌지의 상황에서 컬럼의 값이 아닌 다른 값을 제공할 때 사용.
문자열 함수
문자열의 길이 반환: length(값)
대문자 변환 upper(값)
첫 글자만 대문자로 변경(공백 이후 글자에도 적용됨) : initcap(값);
문자열 안에서 특정 문자열의 시작 인덱스찾기: instr(값,찾을거);
instr(값,찾을 문자열,시작인덱스) - 시작 인덱스부터 L->R 검색 수행.
ex) instr('ABCDE', 'D') // 4가 나옴, 위치(숫자값이 리턴)가 반환됨,
instr('ABCDE', 'Z') // 만약 없는걸 찾을려면 0이나옴.
-시작인덱스 이후부터 검색
instr('BACAZZZ' ,'A', instr( 'BACAZZZ' ) +1 ) //처음 A다음에 나온 A의 인덱스
자식문자열 얻기
substr(값,시작인덱스,자를글자수)
substr('ABCDEFG') //여기서 CDE자를려면?
substr('ABCDEFG',3,3 )
문자열의 앞 뒤 공백 자르기:
trim(값); trim(' A BC ') => 'A BC'
문자열의 앞 공백 자르기
trim(값); ltrim(' A BC ') => 'A BC '
문자열의 뒤 공백 자르기
trim(값); rtrim(' A BC ') => ' A BC'
문자열의 앞, 뒤에 특정문자 채우기 => 동일한 길이의 문자열을 얻을 수 있다.
문자열 앞에 특정문자 채우기
lpad(값,총글자수,채울문자열)
lpad('ABCDE',10,#) => #####ABCDE
문자열 뒤에 특정문자 채우기
rpad(값,총글자수,채울문자열)
rpad('ABCDE',10,#) => ABCDE #####
문자열 합치기: concat(값,합칠문자열) ||와 비슷
조건함수
decode : PL/SQL에서는 사용할 수 없다...
조건을 부여하고 조건에 맞을때 짧은 코드를 실행해야하는 경우
사용)
decode(값, 비교값, 실행코드, 비교값,실행코드,,,,,,, 비교값이 없을때의 실행코드)
case문
select의 조회컬럼에서 사용됨
조회된 결과로 비교하여 다른 코드를 실행해야할 때 사용.
조회된 결과로 비교하여 실행돼야하는 코드가 길 때 사용함.
문법)
select case 컬럼명 when 비교값 then 실행코드
when 비교값 then 실행코드
when 비교값 then 실행코드
else 비교값이 없을 때 실행코드
end alias,
다른 검색할 컬럼들,,,,
문자열 함수 치환.
replace
사용법)
replace(값,찾을문자열,치환할 문자열)
값은 컬럼의 값이 될것임
변환함수
문자변환: to_char
숫자-> 문자열로 바꾸기 (2024-> 2,024)
//패턴의 길이게 데이터가 크기보다 작다면 적용결과가 ###으로 반환됨.
//설정한 컬럼의 데이터형 크기만큼 설정하자
to_char(값, ' pattern ' ) // 0패턴: 데이터가 존재하지 않으면 0을 채워서 보여준다.
//to_char(2024,0,000,000) => 0,002,024
9패턴: 데이터가 존재하는 것 까지만 보여준다.
to_char(2024,'9,999,999') => 2.024
날짜 -> 문자열로 변환
to_date(날짜,패턴)
이때 패턴에 패턴문자나 특수만자가 아닌 문자열을 사용하면 error 발생 => "문자열" 이렇게 넣어야함
패턴이 길면 error 발생
년-y , 월-mm , 일-dd
요일-d 숫자로 된 요일 얻기 (1-일요일 2-월 3-화 7-토)
dy- '월' , '화'
day- '월요일' , '화요일'
오전/오후- am
시간: hh:12 시간제 == hh12 , hh24-시간제
분: mi
초:ss
분기 -
날짜변환
날짜형식의 문자열을 날짜로 변환: to_date
to_date(날짜형식의 문자열, '패턴');
숫자변환
숫자형식의 문자열을 숫자로 변환: to_number
to_number()
집계(그룹)함수
모든 컬럼의 값을 모아서 하나로 만드는 일
group by절과 함께 사용하면 그룹별 집계를 얻을 수 있다.
여러 레코드가 조회도는 컬럼과 함께 사용되면 error가 발생
where 절에서는 집계함수를 직접 사용할 수 없다.
count: 레코드의 총 수를 얻을 때 사용( null인 컬럼은 count에 포함하지 않는다.)
사용법)
count(컬럼명)
합을 구하기
sum: 컬럼의 합계를 구하기...
sum(컬럼명) => 합게를 구할수 있다 ex> 연봉의 총함
avg: 컬럼의 평균을 구할때 사용
avg(컬럼명)
max: 컬럼의 값중 최대값을 구할 때 사용
max(컬럼명)
min: 컬럼의 값중 최저값을 구할 때 사용
min(컬럼명)
집계함수는 group by 절과 함께 사용하면 그룹별 집계를 얻을 수 있다.
select 컬럼명,집계함수(일반컬럼) //일반컬럼에는 그룹별 집꼐를 얻기위한 컬럼이 들어감
//group by절에 포함되지 않는 컬럼 사용 가능
from 테이블명
group by 그룹으로 묶여질 컬럼의 이름
그룹별 합(소계)과 총계를 얻기
rollup, cube사용
사용법)
소계 후 전체 합계 얻기
group by rollup(그룹으로 묶을 컬럼명)

소계를 먼저 얻고, 총계를 얻을 수 있음
전체합계 후 소계 얻기
group by cube(그룹으로 무끌 컬럼명)
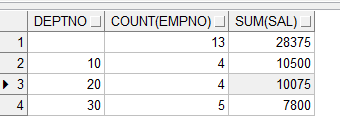
rollup과 cube는 여러 컬럼이 그룹으로 묶이면 다른 결과가 보여진다.
사용예)
group by rollup(컬럼명,컬럼명)
-소계 후 합계가 출력되고, 가장 마지막에 총계가 출력됨.
cube
group by code (컬럼명,컬럼명)
그룹별 전체합계가 먼저 출력된 후 합계와 소계가 출력된다.